Bypass the 2 MB Limit Without Shrinking Your Workflow
· 3 min read

The 2 MB per-payload limit in Cadence does not come with a helpful error. Your workflow does not receive a graceful degradation notice. It just fails. And if you have never hit the limit before, the stack trace is not obvious about what happened.
The claim-check pattern solves this completely. Instead of compressing a large payload and hoping it fits, you offload it to an external blob store and write only a small reference into Cadence history. The limit no longer applies to your payload; only to the reference, which is always tiny.
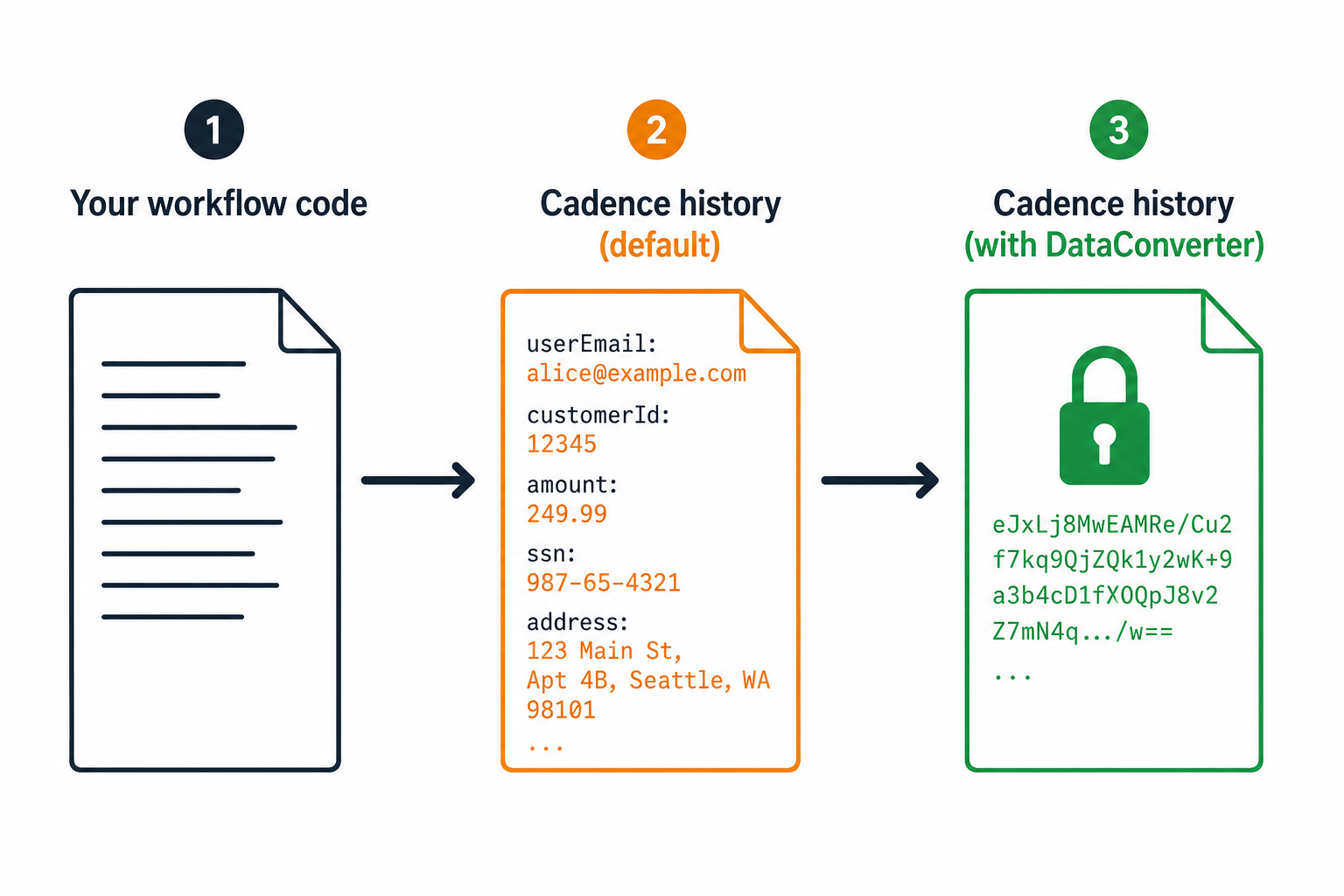 This is not a bug. It is how Cadence works by design, and it is the right default for most workloads. But three problems follow from it in production, and most teams hit at least one of them before they know the solution exists.
This is not a bug. It is how Cadence works by design, and it is the right default for most workloads. But three problems follow from it in production, and most teams hit at least one of them before they know the solution exists.