Batch Actions UI: Manage Thousands of Workflows at Once
· 4 min read

What happens when a bad deploy sends thousands of workflows into a broken state? Or when you need to signal an entire cohort of workflows to advance past a checkpoint?
With Batch Actions, Cadence Web lets you select a group of workflows and act on all of them at once, right from the browser.


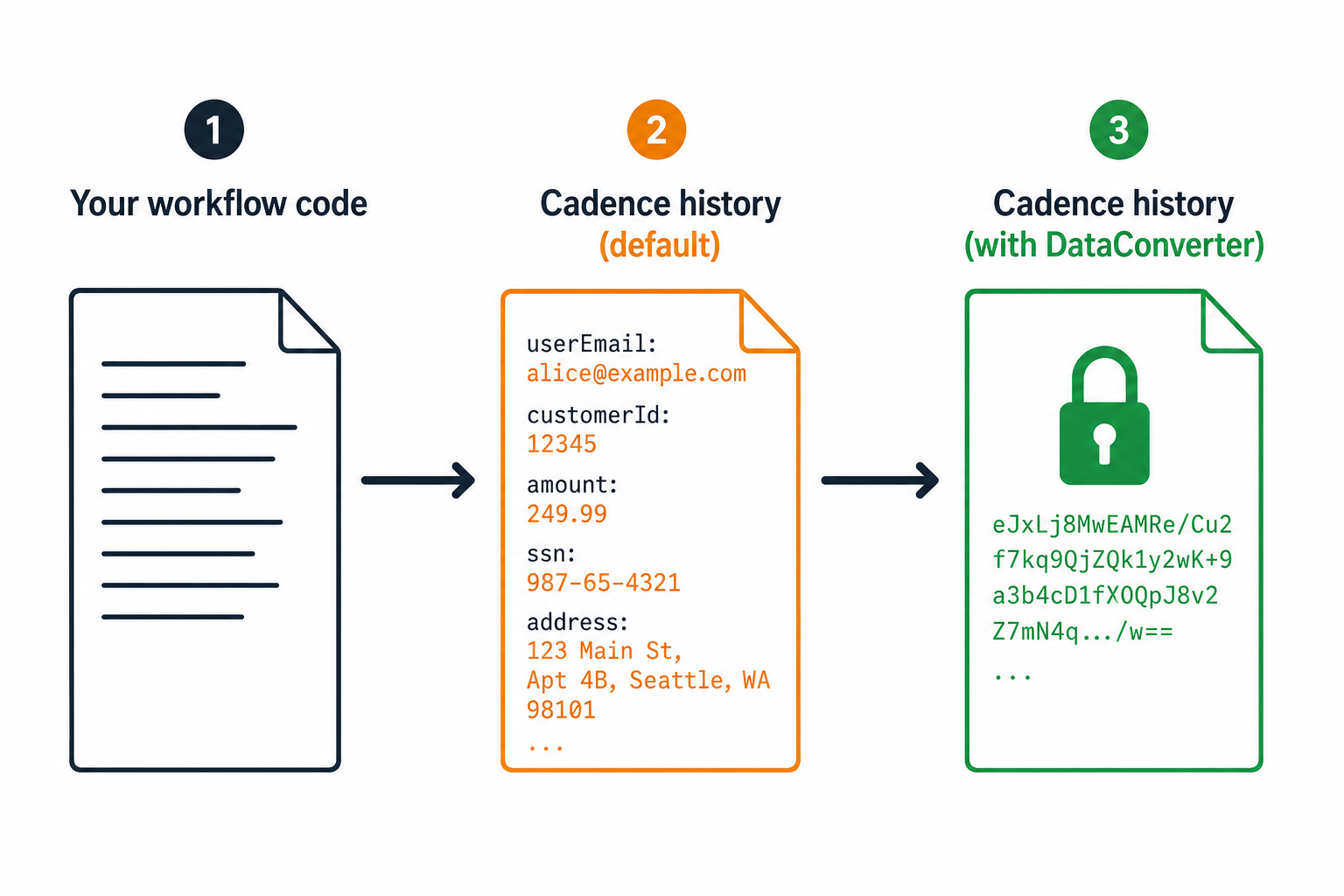 This is not a bug. It is how Cadence works by design, and it is the right default for most workloads. But three problems follow from it in production, and most teams hit at least one of them before they know the solution exists.
This is not a bug. It is how Cadence works by design, and it is the right default for most workloads. But three problems follow from it in production, and most teams hit at least one of them before they know the solution exists.


